人名的处理及生成机制
汉字姓名(包括汉语音译名)一般分为姓氏与名字两个部分:姓氏有单姓和复姓,长度并不确定,有时候人名是没有姓氏的;印象中的汉名一般为一到二个字,但古人也有大于两个字的多字人名,音译名的长度则更加不受限制。
初始的人名资料一般包括人名本身,以及相关的人物信息。
考虑到资料特点、命名规律以及目前生成器作为一项网页工具的性能,现采用以下逻辑。
处理姓名
处理初始的人名资料可以概括为两个步骤:
- 拆分姓氏和名字,将姓氏作为单独的构件。
-
对于名字:
- 单个字的名字、不宜拆分、有固定意义的多字名字,作为
整体名字构件。 - 其它名字,则视具体情况拆分为两部分,作为名字的
构件一与构件二。
- 单个字的名字、不宜拆分、有固定意义的多字名字,作为
当有朝代、民族、性别、年份、地区等足够的相关信息时,在拆分的各个步骤中,判定是否需要对该人名及相关构件进行特殊标注。但由于这些信息并不完备、格式并不统一,取决于各个来源的特点,进行了不同程度和规则的额外判定和筛选。
多字名字不作拆分的情况
- 超过两个字的固定的一个词。比如
修多罗、小娘子。 - 有特殊意义的双字名,尤其是单字有负面意义、结合起来“负负得正”的。比如
去疾、毋死、解忧。这部分的人名目前只处理了一小部分。
多字名字拆分为两个构件的规则
一般拆成长度接近的两份。少数情况下特判。
特殊标注
对于资料相对较多的少数民族姓名、以及特殊身份的人群进行了标注:
不严格的分类
需要注意,由于数据库的标注完备度以及史料的局限性,所有的分类都可能仍有不同程度的误判、漏判,在准确性、难度、数据规模上都有斟酌取舍。分类并不严谨且各类别的判定规则和范围并不一致。构件也可能包括少量称号、封号。具体的分类标准包括原始资料附带的人物属性(地域、族群、郡望、年代、姓名本身等)与结合历史知识作出的划分。
作者本人亦没有明确靠谱、严格统一的标准。可以将此视之为一项尚未完成且难以完成的工作,欢迎提议完善。
未完成
由于细分规则较为繁杂,此表格并未完成。
| 类别 | 判定规则 | 注意 |
|---|---|---|
| 契丹人及关联族群 | 根据郡望(CBDB的属性c_choronym_code='契丹总') |
未考虑父名制这样的特殊命名规则 |
| 女真人 | CBDB之郡望c_choronym_code='女直'、知识图谱之头衔'首领' in Titles |
由于族源及部分姓氏重合的关系,可能混入了满族人名 |
| 满族人 | 基于元明清三代的人名是否为八旗人、是否不是汉军旗、蒙古军旗的人,姓氏是否为满族姓氏 | 由于考虑了八旗人名,其中可能仍然包括不在此类的 |
| 鲜卑人 | 包括关联密切的族群、广义的鲜卑附属、别支,比如柔然。根据姓氏、郡望推断。 | |
| 蒙古人 | 姓氏、清朝八旗中的蒙古军旗除去其中的非蒙古人、地址特判、郡望 | |
| 党项人 | 1) 西夏蕃姓、蕃名。全部来自《西夏姓氏辑考》一书。书中已说明蕃姓、蕃名、汉姓、汉名的区别,我目前尚未按族群细分; 2) 元代唐兀人名,c_choronym_code='唐兀氏'可能是蒙古语的汉语音译名。需要注意不同来源的区别。 |
关于第二类,作者并不知道如何区分蒙古语译名与非蒙古语译名,请将元朝时期的这部分人名作为特殊情况 |
| 回鹘人 | 回纥、畏兀儿、维吾尔人。根据姓氏、具体名字、族属判定。 | 作者并不知道如何区分蒙古语译名与非蒙古语译名,请将元朝时期的这部分人名作为特殊情况。维吾尔人有多个来源,可能不太适合归入,但目前也不知道如何单独区分。 |
| 突厥及其关联族群 | 突厥人、突厥语族群、或相较其它族群与突厥关联更大的族群。某些族源可能是突厥的部族、不知道是突厥化的蒙古人还是蒙古化的突厥人的,不管确定与否,目前都分类在这里(尽管其多数元代的人名可能是蒙古语音译,多数蒙古部附属的部落族源存疑且在不加细究时经常笼统地被认为是蒙古部落),比如弘吉剌、塔塔儿、葛逻禄、汪古、克烈、乃蛮、灭里乞、康里。根据姓氏、从各来源发现的具体人名、郡望、民族推断。 | 作者并不知道如何区分蒙古语译名与非蒙古语译名,请将元朝时期的这部分人名作为特殊情况 |
| 回回人 | 元朝时期的定义,主要基于元朝人名分类及数据库的属性标注,不等同于其它语境下的同名群体。根据郡望、地址、具体人名推断,可能有问题。 | 作者并不知道如何区分蒙古语译名与非蒙古语译名,请将元朝时期的这部分人名作为特殊情况 |
| 吐蕃人(v2.1.0新加) | 全部来自黄布凡、马德《敦煌藏文吐蕃史文献译注》所附人名索引。吐蕃人名较长,但最多拆做两部分,不占据姓氏构件的位置。拆分尽量考虑了对应的原语言人名的音节和意义(如有)。 | |
| 外来僧人 | 从具体姓名中收集的列表 | 多数是梵语人名,少数不是,暂且混用 |
| 汉名僧人 | 一般是释、僧、尼、沙门、(仅限晋朝)竺等开头的汉名。 |
数据中存在宗教意味较明显的、与直接使用俗名的两种情况。使用原姓氏的没有明确的人物属性信息,暂不标记。 |
元朝
作者不太熟悉,判定过程中基本是现查的。但此时期的人名具有独特特征,也存在不同族属的人取同一个名字的情况,大部分划分为非蒙古人的少数族群的人名可能系蒙古语音译,按需或应独立使用。 在判断的过程中,使用了以下资料及网络检索(不完全、不规范列出):
- 《元統元年進士錄》
- 雷纳·格鲁塞《蒙古帝国史》
- 蕭啟慶《元代蒙古色目進士背景的分析》
- 汪古人肯定是突厥人,乃蛮人很可能是突厥人。汪古人是沙陀突厥人的后裔(伯希和,《通报》,1929年,126)
- 王风雷 [蒙]S.巴图呼雅格《蒙古人当中的唐兀后裔》载于《庆祝蔡美彪教授九十华诞元史论文集》
需要注意的是,关于具体的部族,其族源为何,学界基本说法不一,此处仅是对每一个这样的部族选择了一个感觉更合适的分类。
存在汉人取蒙古语名字的情况,可见李治安《元代汉人受蒙古文化影响考述》。本工具尚未加入这样的考虑,除了少量超过二字的名字具有特殊判定、部分未进行标注的非汉名与汉姓搭配的情况,没有符合经验分布的汉姓+非汉名的生成实装。
外国人
虽然从来源上看,中国古代的姓名,并不仅限于(各时期的)中国人,但关于外国人名,目前并没有严格的、统一的标准。
数据库中的外国人(指现代的国外)是否收录没有明确的定义,但目前的处理流程中,仅收录了外来僧人和回回人。
CBDB中大量具有中文名的明清时期的传教士不录。
阿速人等作者认为语言来源太多不宜合而为一的外国人虽有标注,但全都不录。
由于在所有的来源中,明确标注了民族、郡望、部族的仅占海量人名的一小部分。在经过大量的额外判定后,数目在现有数据库中仍然不足的(比如藏族人名)、或者不足且无法兼容现有机制的(比如南诏人名),或者暂时不录,或者可能混入了其它类别之中。目前暂时在生成姓名的最后一步对以下类别进行非常简单的特判,并在添加特殊标记符号及人名详情页的注释:
| 类别 | 判定规则 | 注意 |
|---|---|---|
| 魏晋南北朝时期可能受宗教影响的人名 | 只看人名中是否有玄道之僧法昙慧圆。 |
没什么好说的,需要自行决定。只在汉名之中判定。 |
| 匈奴姓氏 | 只看姓氏是否为破六韩 须卜 呼延之一 |
使用与汉名一致的生成机制 |
| 羌人姓氏 | 只看姓氏是否为弥姐 苏农 夫蒙 荔非 钳耳 莫折 彡且之一 |
使用与汉名一致的生成机制 |
外来僧人的名字
需要额外注意的是,外来僧人的名字可能被拆成三个部分。为了兼容现有的姓名结构,将第一部分作为姓氏构件,但并不一定是实际的人物姓氏。
作者检查了这些人名的原语言音节与意义,以得到准确的汉译名拆分。重新组合之后,发音上应该是没有大问题的,但重新组合的结果并不一定能对应到具体有意义的单词。
举例
浅择几例人名展示拆分规则。以下人名除非单独声明,均为随机生成,不代表真实人物及作者个人偏好。
| 例子 | 拆分方法 |
|---|---|
| 生活在汉朝的刘去疾 | 姓氏:刘+名字·整体:去疾 |
| 生活在北朝的长孙须摩提 | 姓氏:长孙+名字·整体:须摩提。由于可能经历了孝文帝的改革,从拓跋改姓,所以标注族源为鲜卑(在此之前的长孙则保留为汉姓);须摩提意味着对应的人物可能受宗教信仰而起名,所以另外标注;由于是女性人名,后期再进行过采样。 |
| 生活在五代的赵迎新小娘子 | 姓氏:赵+名字·构件一:迎新+名字·构件二:小娘子。真实人物,来自《後周武官單州刺史趙鳳墓誌銘并序》“……有女四人:長曰榮姐,次曰興姐,次曰迎新小娘子,幼曰姪女羅姐。……”。其实我也不理解为什么这么叫……但是存在即合理。 |
| 生活在元朝的孛而帖穆尔 | 姓氏:无姓+名字·构件一:孛而+名字·构件二:帖穆尔。来自被标注为“畏兀儿”的数据。此名字大抵是蒙古语音译,但我们向上追溯族源到回鹘人,以族源标注这个名字。 |
| 生活在唐朝的勿提提羼鱼 | 姓氏:无姓+名字·构件一:勿提提+名字·构件二:羼鱼。真实人物,对应的梵语音译名是Utpalavīrya,意译是“莲华精进”;我们又能查到Utpala是优钵罗花(蓝莲花),vīrya是精进的意思,那么可以建立“勿提提-Utpala-莲华”,“羼鱼-vīrya-精进”的对应关系。标注为外来僧侣。 |
| 生活在明朝的尉迟妙宁 | 姓氏:尉迟+名字·构件一:妙+名字·构件二:宁。一个常规名字的标注。 |
| 生活在清朝的乌梁海熙春 | 姓氏:乌梁海+名字·构件一:熙+名字·构件二:春。真实人物。标注为蒙古人。名字可以拆成两个构件。由于是女名,后期再进行过采样。 |
生成姓名
基于处理得到的构件,姓名照姓氏(可以为空)+名字的格式生成,名字则是整体名字或构件一+构件二的格式。
生成时视具体的选项设定以及姓名的特殊情况作进一步的筛选。
筛选来源
参照人名资料的来源及处理方法中所展示的数据规模,可见明清时期的人名资料相对其它所有来源的总和而言是规模巨大的。勾选全部来源将会导致设置时轻微的卡顿(1)。您可以根据具体的需求,只勾选某些时期的人名来避免这个问题。关于来源的详细说明,请同样参照此文。
- 实际上这是实时显示可用范围与延后显示(但是在生成人名时稍有卡顿)之间的取舍。
筛选姓名
这方面的功能均在姓名选项页中。
多字构件判定规则的区别
注意作为整体的名字构件,一个字的,与构件一共享名字一的选项设定;多字名,第一个字适配名字一的设定;第二个字适配名字二的设定。比如设定二者为左右结构,那么划分为整体构件的敦狐也是符合筛选条件的。
构件一和构件二的构件之中,如果只有一个字,则直接适配对应的设定;如果有多个字,则取最后一字适配设定,不对其它字作判定。
非汉语音译名尽管也参与筛选,但是字形、字音上的筛选对这部分人名来说,意义大概不是很大。
首先是固定姓氏与名字,如图所示,生成器最无聊的功能,没什么好说的。
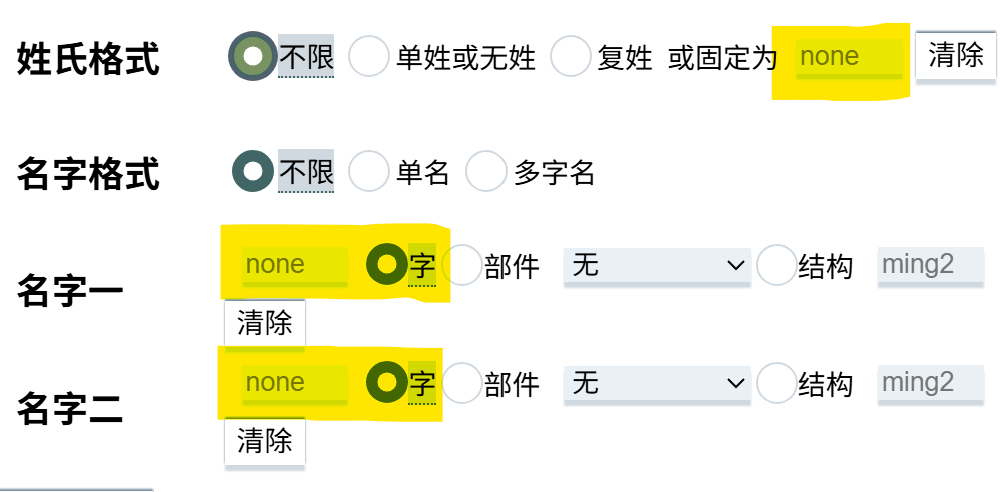
姓氏和名字可以分别设置为单姓、复姓、单名、多字名,同样没什么好说的。

可以按照部件与结构选择名字。部件的下拉列表为预先演算好的范例,可选的部件并不仅限于此,任何字或字的部分都可以作为部件。
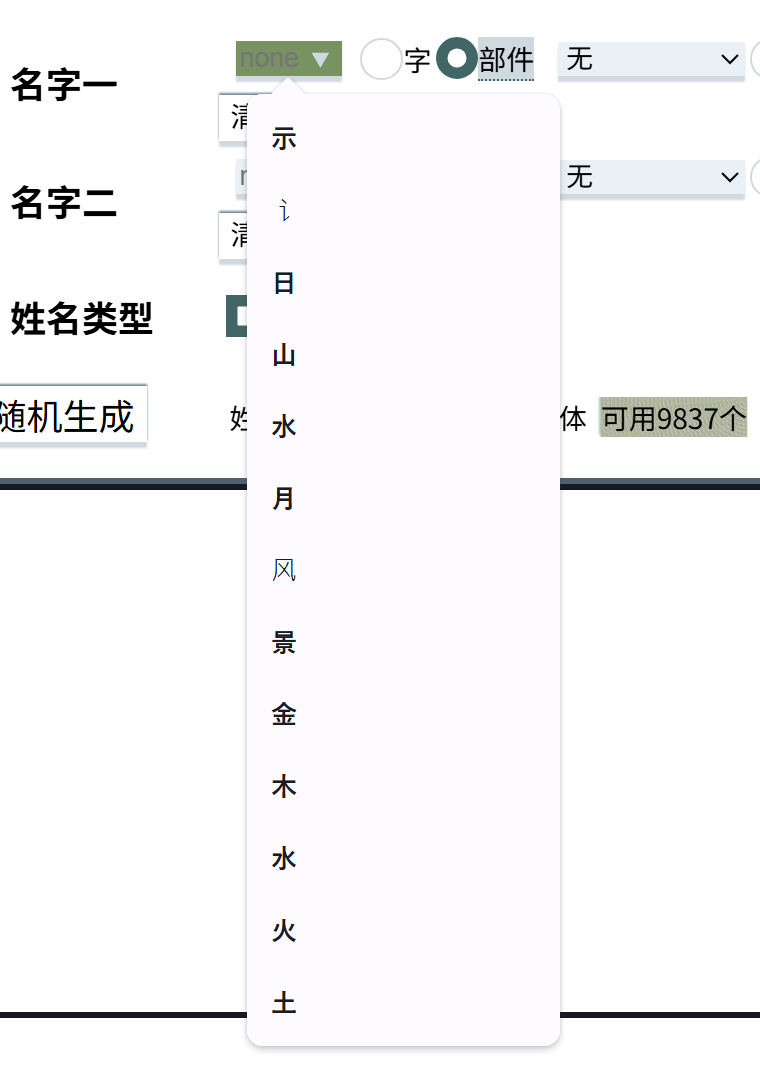
部件
部件并不等于偏旁,而是一个字。请参考IDS 表意文字序列庫 或 zi.tools 字統网上的组字、搜字功能。
比如我们设定名字一包含火作为部件,名字二是包围结构,那么可以得到这样一组返回的人名数据:

首先是按拼音筛选。当前(v2.0.0)的拼音提供的匹配规则是:
- 拼音采用a-z的小写字母加可选数字后缀的格式。数字后缀表示声调(轻声则没有数字后缀)
- 可以用减号
-代替声母或者韵母的位置,匹配任意值。 - 可以用半角问号
?代替声调的位置,匹配任意声调或轻声的情况。
举例说明
| 输入 | 规则 | 结果举例 |
|---|---|---|
| ming2 | 匹配所有能够读为míng的字 | 明名溟茗眀冥洺萌 |
| m-? | 匹配所有声母为m的字 | 妙伯孟明万懋茂敏 |
| -ing2 | 匹配所有韵母为ing且为第二声的字 | 明宁行平瀛亭庭廷 |
| min? | 匹配所有可以读作min、不限声调的字 | 敏民汶湏岷旻慜旼 |
| -2 | 匹配所有可以读作第二声的字 | 文德元廷云承伯如 |
| -- | 无效输入 |
如果我们分别设定两个构件为m-?和-ing2,那么可以得到这样一组人名:

可以发现系统并不能判断多音字各个读音之间的常见程度,而字的多种发音里经常包括罕见的发音。遇到此种情况,请查阅单字的详情页或外链的信息。
然后是切韵音系(虽然作者对这个受众范围产生了一些怀疑,但毕竟 TshetUinh.js 是所有筛选选项中唯一一个 Javascript 库,且我们古代人名生成器必然也优先需要古代读音)。当前(v2.0.0)的版本优化了排版,于是严格保留了各项音韵属性和原始的、未经转换的取值(1),仅将声母、韵母按照组与摄合并陈列在最上方,以便做出更宽泛的选择。用户可以视需求对其中一到多个属性进行设定。
- 有心之人将会发现这是默认的简体界面之中唯一没有经过机翻转换的。

上图展示的是所有展开选项的拼接,并非实时界面截图。
语音
TshetUinh.js 的资料来源是《广韵》。《广韵》只反映了中古某一段时期的汉语语音系统,显然不能代表所有时期的读音。请在使用时牢记这一点。
如果我们分别设定两个构件为流攝和影組,那么可以得到这样一组人名:

但一般来说,设置过多属性会导致可用姓名不够,削减人名的“自然度”。例如,分别设定为?開一?歌平和端組、開一??去,所得到的可用双名构件将分别只有25个和55个,由于构件的频度不同,返回的内容将会略显同质化:

增加释义反查,释义反查有两种模式:智能语义匹配、字符串模糊匹配。注意:输入释义后,鼠标点击或触屏点击输入框外部的其它区域,退出聚焦输入框的状态后才会启动查询。
1.智能语义匹配。使用语义向量模型、基于英文释义构建的匹配功能,支持中英文短语。输入中文将自动识别并翻译为英文。预处理数据集与程序均部署在 Hugging Face,基于地区限制可能需要设置网络代理。消耗额外的网络流量,耗时长。长期无人使用,该功能将处于睡眠状态,如能正常访问,请先发起一次查询请求等待功能被唤醒,或在 Hugging Face 页面唤醒该功能。
模型完全基于语义,能够理解并处理:“豪放不羁”、“新生的植物”、“某某、某某和某某”、“某某或某某或某某”等语义,或者说是意象,并返回语义接近的字。但不能处理词性的限定(“动词、名词”);也不能准确理解或者过于佶屈聱牙的表述,如“渊懿美茂”;也不要添加与释义无关的内容,全部翻译结果都会参与近似度匹配,如“请为我返回与鸟类有关的用字”,会匹配释义与全句“Please return to the bird-related words for me”而非与 bird 类似的用字。
程序内已做了针对模型主观倾向或偏见的预处理与后处理,但模型自动翻译可能仍然不准或有偏见。如输入中文,可在查看返回的翻译结果后,调整为合适的英文表述。
该功能的一个副产品是:古汉语语义关系图谱。
2.基于英文释义的字符串模糊匹配。仅支持英文释义及中文单字反查。使用 Fuse.js 实现英文释义的模糊匹配查询。部署在网页内,即时返回,但字符串近似度与语义近似度有所区别,亦需要用户具有适应此版本所用英文释义(Unihan与《上古汉语新构拟》词表)的、较好的英文概括能力。
如图所示。由于并不严谨的分类,在选定具体类别时,可以额外对来源时期进行设定。由于存在“非汉姓+汉名”的情况,可用构件与姓名类型并不严格一致。

一些问题
为什么拆成两个构件?
众所周知的生成拟真程度较高的名字(不限于人名)或者广义的各种文本的方法有很多,比如各种神经网络或者较为朴素的马尔科夫模型。但一般来说,这样的文本需要由很多个元素组成,就人名而言,可能体现为需要很多个音节。
但大部分汉名是单名或双名,并不适合、也没有必要使用这样的模型。
具有很多个音节的音译名,其数据规模相较不大,而且难以探究原语言的音节与汉语音译的对应关系。而且这样切取的方法,古已有之。
综上,考虑到生成算法的兼容性,大于等于两个字的名字,大部分拆分为两个构件。
为什么名字的两个构件随机独立生成?
目前来说,作者认为没有额外的必要去考虑名字各部分、甚至姓与名之间语义上的关联性。如果加入了名字构件联合使用的频度信息,与之前常见的、随机姓氏和完整的名字、或者限定了具体字辈的人名生成器没有什么区别,而且增加了工具的文件大小。故而除了单名与少量特殊名字单独作为不可拆分也不可与其它名字构件组合的一个构件,并不额外考虑语义关联性。
取而代之的是人名详情页会有各时期或来源的高频次常用名的信息提示。如随机生成的名字恰好是常用名,则显示来源及频次。
为什么只有切韵和拼音?
别的还没加。